Lab #5: Polymorphic Type Inference for Simple Expressions
Assigned: Thu 7 Mar 2002Due: Thu 28 Mar 2002
Contents
Problem description
This lab constitutes another in a series of labs concerned with the implementation of a compiler for a simple expression language. With this lab we implement type-checking and handle a few other issues of "static semantics," also known as context-sensitive syntax.Type-checking is important for two reasons: first, when we check types on an expression we may catch programmer errors, allowing us to reject the expression out-right and refuse to continue with compilation. In many cases, there is no real alternative, since in the presence of type errors it may not be possible to do anything sensible at run time. Second, type-checking also gives us invaluable information for use at run-time when it succeeds. That is, having the information about types discovered in this phase may be crucial to the next phase, in which we actually generate machine code which implements the semantics of the expression.
As a quick example of static analysis, consider this expression (and the one below):
IF ((x=READ)+2) ^ (y=READ) THEN 17 ELSE F END
In the first expression, the conditional part of the IF doesn't make sense, since
the expression involving x is clearly an integer, and yet it is "anded" with y,
which we would therefore expect to be READ in as a boolean value. Also, note that
the THEN and ELSE branches of the conditional return values of different types,
and therefore it isn't clear what the type of the whole expression is intended to be.
As mentioned above, we will also do some (trivial) non-type-based checking in this phase, namely verifying that every variable is assigned before it is used. It is possible to keep track of this information using roughly the same techniques we use for type-checking, so it is natural to include this check here. The following example fails to check because the variable x is used before it is assigned: this example therefore illustrates the fact that, in our language, expression evaluation is done right-to-left, that is, right arguments of binary operators are evaluated before the left ones are. (On the other hand, the IF expression, which is not an operator, evaluates the conditional first, and then evaluates only one of the branches.)
x=3 + x * 5
As with the last lab, this one is not concerned directly with semantic issues. You will nevertheless do well to keep the intuitive semantics from the last lab in mind, as it will not only help to understand what you are supposed to do (and why), but also lay the foundation for the later phases of implementation.
Types and type rules
Our type language will essentially include only two basic types,Int
and Bool,
representing integer and boolean values, respectively. Of course, the operators
of the language in some sense have types, but we won't need to manipulate these
separately (i.e., they will be handled as part of the syntax). We can get away
with this approach since operators can only be applied to arguments, but cannot
occur in any other context.
We will also need to keep track of "unknown" types, during the type-checking process , i.e., to somehow indicate that the type of a variable or expression is not yet determined. By way of example, the type of a READ expression is in general unknown until we examine the surrounding context. This "unknown" status can propagate quite far out of a READ expression, as the value read in can be, e.g., assigned to one or more variables. On the other hand, we may need to keep track of several "unknown" types simultaneously, even though we know they represent different types. For example, consider an expression which has two READs embedded in it, as follows:
... (x=READ) ... (y=READ) ...
We know that the type of x matches the first (from left-to-right) READ and that
the type of y matches the second, and yet we must in general keep track of these
"unknowns" separately. The idea of several "unknowns" should suggest the use of
multiple variables, in the same sense that the word "unknown" is used
in algebraic contexts (e.g., solving equations in several "unknowns"). Although
our language is simple enough that we might get away with something less formal,
we will see in our text that the use of type variables is the standard
technique for keeping track of such "unknowns". We will implement type variables
using a simple place-holder technique; see below for details.
An important point about type variables (or "unknowns"): if the type of a whole expression or any sub-expression remains unknown at the end of type-checking, we must either reject the expression as ill-typed or be prepared to do dynamic (i.e., run-time) type-checking on it. You are not required to do dynamic typing, i.e., you may reject any expression that would require it as being ill-typed. See below for examples of such expressions, and lecture on Chapter 4 topics for how dynamic typing might be implemented.
Here is an informal (English) specification of the typing rules we will use for our expression language (see this link for the grammar):
- integer literals (<int-lit>) have type
Int; - boolean literals (<bool-lit>) have type
Bool; - variables (<var>) may either have type
IntorBool, but it must be used consistently within the whole expression; - a
READexpression may have either typeIntorBool, as long as its use is consistent with the rest of the expression; - an assignment expression
V = Emust have the same type on both sides (the variable and the expression) and this common type as its own type; - when a post-fix operator is applied to a variable,
they should have compatible types (i.e., integer
operator and integer variable or boolean operator and
boolean variable), and the type of the whole expression
is this common type;
- when a binary arithmetic operator is applied to two
expressions, both argument expressions and the whole
expression itself should have type
Int; - when a binary boolean operator is applied to two
expressions, both argument expressions and the whole
expression itself should have type
Bool; - when a binary relational operator is applied to two
expressions, both argument expressions should have the
same type, either
IntorBool, and the whole expression itself should have typeBool; - the first sub-expression of an
IFexpression should have typeBool, but the other two sub-expressions may have typeIntorBool, as long as they are both the same (the type of the wholeIFexpression is also this common type).
Most of these rules should seem pretty obvious once you reflect on them for a bit. You may also wish to fall back on your intuitive understanding of the semantics of the expressions to help you understand how they should be typed. Although we could use a formal type system (e.g., with inference rules) to capture the intended notion of typing, it will probably be easier for everyone to use the informal rules above.
Some sample expressions
In order to provide some concrete guidance, here are some example expressions along with the type-checking results we would expect from each:- 2+3*5
type-checks OK with type Int.
- (2 < READ) | F ^ (READ==T)
type-checks OK with type Bool (note that one READ has type
Int, the other typeBool). - ((x = READ) + y) > 2 | (z = (y = READ))
fails to type-check, since the type of y must be both
BoolandInt(it is the right-hand argument of both a "+' operator and a "|" operator). - IF (x+2) > 3 THEN x-1 ELSE 17 END
fails to check because the variable x is never initialized.
- IF b = READ THEN 37 ELSE T END
fails to type-check because the "THEN" and "ELSE" branches of the "IF" are not compatible.
- IF (x = READ) == (y = READ) THEN x > y ELSE x < y END
fails to type-check because the types of x and y are not determined by the context of the expression: they could either both be
Intor both beBooland the code would make sense (remember that relational operators are defined at both types).
Strategy for type-checking
Type-checking for this simple expression language is also fairly simple: we just need to keep a "type" field associated with each node in the expression tree. These fields will need in general to exhibit a behavior similar to a variable (i.e., they will need to be able to be "filled in" and shared), so the natural thing to do is to make them a reference to a new class of object which behaves like a simple memory cell. Now type-checking is just a walk around the expression tree (a recursive algorithm would be natural) associating and updating type nodes or cells as the tree is traversed.
For literals, the value held in the cell can be immediately set to a
fixed type (Int or Bool); for a READ expression
the value can be set to indicate "unknown". For variables, the value should
be looked up in a simple symbol table (you may use a hash table or even
something simpler if you like), so that every occurrence of the variable
uses the same type cell.
The use of these "cells" or variables will allow you to easily propagate
information around the expression (i.e., forwards or backwards, in some
sense) about constraints on types. Following is a suggestive picture of
the cell scheme in use, showing an expression tree, a type node and access
through a symbol table to get the type of the variable x. The picture
tries to suggest a stage at which x's unknown type has been discovered
to be
When checking operators and constructs such as the "IF-THEN-ELSE-END" form,
you may need to check that arguments or branches have specific types
(e.g.,
Finally, the analysis necessary to determine proper use of variables (i.e.,
that they are assigned before they are used) can be as simple as keeping
a boolean flag associated with each variable to denote its status, visiting
nodes in evaluation order, and checking to make sure each variable is set
before it is used.
Int.
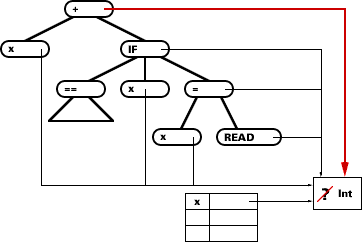
Int for arithmetic operators or Bool
for the first sub-expression of an IF) or that they have common types
(e.g., the arguments of relational operators or the "THEN" and "ELSE"
branches of an IF). In such cases, you may need to over-write an unknown
type with a known, fixed type or to join together (or "unify") two
nodes (e.g., if the branches of an IF are both unknown, but now are
known at least to be common).