[For a black-and-white version of this lab, suitable for people with certain visual disabilities, see this link.]
The purposes of this lab are to:
StopWatch class), a class that uses randomization
(the PhoneNum class), and a larger testing application
that compares multiple data structures in terms of their performance;
Below you will find:
Names module that
I have provided for you;
random library;
PhoneNum class
that you will provide (based on Names);
datetime library;
StopWatch class that you will write;
TimingLab module
Dictionaries in Python match up keys and values together in an overall
structure that contains several such “pairs”, with just a colon
(:) to separate them, and curly braces around the whole structure.
On the other hand, lists can contain many types of values—but in particular,
they can contain pairs of values: two values put together with parentheses
and a comma. In fact, there is a close correspondence between dictionaries and lists
of pairs, at least in terms of their Python syntax:
{ 'a':1 , 'b':2 } # a dictionary, with keys and values
[('a',1), ('b',2) ] # a list [] of pairs (), with left and right parts
>>> d = {'a':1, 'b':2} # a simple dictionary
>>> d['b'] # looking up the value 2 based on the key 'b'
2
lookup a right part in a list-of-pairs
by finding the corresponding left part. This shouldn’t be too hard:
just write a loop to run down the list and look for the correct left part
(as specified in a parameter by the caller) and when you find it, return
the corresponding right part. (Of course you must raise an exception or similar
if the left part being sought is not available.)
Task: Write a function
lookup(key,lops)wherekeyis sought on the left sides of pairs in the list-of-pairslops. Then return the right part of the pair as the result (and if no key-pair is found, you maypass, returnNone, or raise an exception (such asKeyError).>>> lop = [('a',1), ('b',2)] >>> lookup(lop,'b') 2(Note that you should in particular return the resulting right part of the pair, not just print it: printing something out is great for a user or programmer at the console, but programs will in general need to get a result back as a returned value for it to be useful to whichever part of the program needs the value next.)
At this point, you should recall some of the charts from our textbook, the ones which compare the performance of dictionaries to lists: although lists are more familiar to many beginning programmers, dictionaries seem to outperform them in significant ways: many operations that are O(n) on lists are just O(1) on dictionaries!
A third option for making and using a ‘lookup structure’ would be to use your own linked lists, as implemented in lab, to “host” the pairs in the list-of-pairs. We know that for some operations, at least, linked lists can outperform native Python lists. (Spoiler alert! As you might guess, however, this is not one of those cases: trolling through a list, item by item, searching for something, is bound to take time proportional to O(n), just because we may, in general, have to look all the way down the list, one item at a time. The fact that dictionaries can do something essentially equivalent in just O(1) time is the unexpected, amazing thing!)
So, in this lab, let’s check out the performance of these three options:
(1) a regular Python dictionary, or
(2) a “roll-your-own” one built from either a Python list-of-pairs, or
(3) one built from a linked list-of-pairs.
Our approach will be to write a short “test harness”: this code will
generate some random-sample based data and then drive it through a few
performance tests, so as to compare the various options. We can time the runs
of the various sample sets we generate, and report those timings out at the
end, in order to make comparisons. We’ll write a short (but useful!)
StopWatch class in order to make the timings.
Along the way, we'll have use to generate random names and phone numbers
(from the Names and PhoneNum modules), using random
number methods from the random library. Finally, we’ll also
use the datetime and timedelta classes from the
datetime library to implement our StopWatch class for
for making the timings, thus practicing the use of standard libraries as well.
For the purposes of a “back-story” to provide context for the lab,
we’ll go to the phonebook for inspiration:
we’ll assume that the (key,value) pairs we will be working with are thus
names and phone numbers, with just a little bit of structure to
them.
We will then generate sample lists-of-pairs and dictionaries of a given size:
call these the general population, or “genpop”. Their
generation will depend on the Python random library indirectly,
since the Names and PhoneNum
modules will use some random utilities. We will also
create a smaller sample population of names to do our testing: for each
name in the sample population, we will look it up
in the genpop list or dictionary, and capture timing data on the results.
By using the same sample and general populations for the dictionary and two
list-of-pairs approaches, we will get a fair comparison.
What about the actual code that we are timing? It will be just the time it
takes to look up a phone number using a name, since this is the aspect of
the competing data structures that we want to compare.
For the list-of-pairs examples, you can use the lookup function you
wrote above, and for the dictionaries you can just use indexing ([ ])
or the dictionary's .get() method. (This is a little easier than
using indexing; see the section called Getting information from a dictionary
at Leticia Portella's blog post
on her favorite python tricks for an explanation of why. By the way: she has other great
stuff on her blog; why don't you take a look around?)
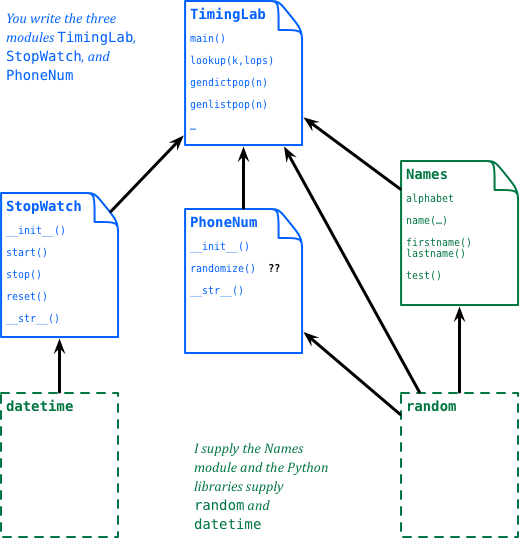
How should we build a project like this? Let’s use Python’s object features to structure things. Below is a suggested overall design, presented in a diagram, where each rectangle corresponds to a class or module:
You don't have to use this specific structure, but if you don't, try to make sure you do so from a place of knowledge, i.e., try to understand my recommendations and why I make them before creating your own design.)
In this diagram, the blue modules/classes are the ones you will write yourself:
StopWatch, PhoneNum and the main TimingLab.
The solid green one (Names) is supplied by me, as an example;
see below. And the dashed green ones are standard
Python libraries. (Diagrams like this are often useful in understanding the
structure of code like this: in the “real world” developers
sometimes use tools that allow them to draw similar pictures and then actually
generate code templates and files automatically from the diagrams.)
Names moduleAs alluded to above, we will need a way to generate names for our phonebook general populations, both the general one which represents the overall “book”, and the more specific ones which represent the test population for lookup.
In order to generate the names, I am providing a definition of a module
of code for you, as both a resource and a model of coding style. In particular,
the file Names.py shows how
you can use the features and functions of the random library to
generate random names.
See here for the actual code file
and here for a colorful HTML version
(with the help of www.hilite.me).
How does this code work? Overall, note that it does not implement an actual python
class (more about that later), but rather just a single variable
(alphabet), a few convenient functions (name,
firstname, and lastname, and a short bit of test code to
make sure everything works (called, unsurprisingly, testrandom is imported.
The idea is that the name function generates random strings of
letters in lengths that can be specified in parameters—it is the real workhorse
of the module. The firstname and lastname functions are then
just “convenience functions” which call the name function
with specific parameters (they are intended to return names of lengths that are typical
of first and last names, with the former being a bit shorter, and the latter a bit longer).
The name function is perhaps easiest read from the inside out, so to speak
—in particular, note that it is a single return statement which calls
several nested methods and functions “layered” one on top of another.
On the very inside (indented furthest to the right) is a call to the
randrange function from the random library: this will return
a parameter k which is essentially a “die roll” that returns
a random number between the minimum and maximum specified.
This parameter k is then used to get some random choices from the alphabet,
namely k of them. So the result of the random.choices call is just
a list of k letters chosen at random. (Note that this scheme will not lead
to very pronounceable names … .) Since the letters are in a python list (as returned
by random.choices), we will want to convert them into a string: for this we
can use the python join method, joining in particular with an empty string
between the letters. (In general, you might want tabs, commas, etc., in between a bunch of
strings when you join them, so the separation string is specified as the one
on which the join method is called.) Finally, we use the python
capitalize method, called on the resulting string of k letters,
in order to make it look like a typical name.
Now the convenience functions firstname and lastname will
return names within specified length ranges. These are the functions your code
will likely call, in order to build a final name to be looked up in the
“phonebook“.
But here is an interesting conundrum: the functions let you create first and last names, but they don’ provide you with a whole name! How will you add these names into your dictionaries (as values to be looked up) and as “right parts” of pairs for your various lists-of-pairs? One idea would be to just “jam” the names together to create a longer string, say with a space in between, and call that a ‘whole’ name. But consider the longer game, the way a more realistic program ought to work in a more realistic environment. What is likely to happen is that names are likely to grow more complex, to include middle names, to allow for hyphenated names, various prefixes and suffixes (such as “Mc” or “Jr.”), to account for various cultural differences (such as different orders of family and personal parts of the name), not to mention nicknames, etc.
What I would like to suggest is that you consider converting my little Names.py
module into one which provides a real python class, say the name class.
That way, if and when the program grew into something more realistic, you would have an
easier route to these various generalizations, should they turn out to be needed. In
particular, you could make sub-classes, or just add features, in order to allow for a
more complex structure to both the names and to the various methods and functions
which would be available to a client for manipulating them.
This would mean that your dictionaries values, and the right parts of your pairs, would be
actual objects of the name class, rather than just strings jammed together,
or pairs of strings, or whatever other ad-hoc solution you might come up with. In other
words, there is an extra “little lesson” of design embedded in the lab here:
you can design a better alternative to simple or separate strings and use it to protect
yourself against the complexity of later changes. This is a hard kind of lesson to learn
on the job in the Real World, so perhaps better to practice in a smaller, gentler context
like this lab.
So, see if you can come up with a simple class that uses my code (feel free to copy and
paste, just credit me in a comment) to allow a client to get a new name
object, presumably by calling the __init__() method of the class.
It needn’t be especially complicated, really just a wrapper around my code,
if you will. The point is not to introduce all (or any!) of the aforementioned complexities:
the point is to make something simple, as appropriate for the current program, but also
to plan for future growth by making careful design choices early.
Note: In order to use python classes and objects for the names
in this program, you will need to compare two name objects to see if they
are equal (and python itself will need to be able to do this for you in order
to implement dictionary lookup and perhaps a few other things). So, how do you make
sure that python can compare two of your objects (ones whose class you
defined) for equality? As usual with python, there is a standard method, using the
usual “underscores” naming style, that you must define in your class.
The particular method name this time is __eq__(…): python will
call this method in order to compare objects of your class to see if they are equal.
How will you compare two names? Well, for our purposes here, if the two first-name
parts are equal (as strings) and the two last-name parts are equal, then the two
names themselves are equal. (In a more realistic version, a lot of tricky situations
would need to be handled: 'Tom''Thomas, etc.)
As for the actual mechanics of defining the __eq__(…) method,
see
this python tutorial on __eq__.
random library
In the Names.py file I have provided, we use functions and methods
from the standard python random library.
This library can help us generate the random data (names and phone numbers)
that will form the basis of our tests. In order to help you in confronting
what is a fairly complex library, this section provides some further notes
on random. (Note that we will not use any
particularly sophisticated techniques in our lab program: a more serious treatment
would likely involve data science issues of distributions of real-world data,
more attention to probability and statistics, and even the use of more
accurate timing tools for that part. But the approach described here will be
sufficient for the purposes of learning about data structures.)
You can find the official documentation on the random library
here at
python.org. (Although we will only use a few simple utilities
from this library, it is worth looking around a bit at the documentation more
broadly, as this is the sort of resource you will be using from now on in
making use of Python’s extensive library tools.) Note in particular that,
due to the deterministic nature of most modern computer hardware, we cannot
generate truly random numbers from Python on a typical machine (whatever
that would even mean: perhaps some quantum feature?). In any case, as with almost
all random libraries, in any language, these “random numbers”
and related phenomena are really only pseudo-random. In Python this means
that they are generated in a mathematical fashion based around the idea of a
seed value, which is manipulated in successive turns to generate sequences
of numbers, that then have fairly good properties relative to theoretical assumptions
and the usual real-world phenomena, such as coins or dice. In any case, the
initial seed values are usually taken from computer clock time, but can also
be specified by the user—the latter approach allows one to run the same
calculations with what amount to the same sequence of “dice rolls”
multiple times in a row, which is useful in experimental contexts.
(Note that the second form does not have the usual range behavior with regard to the>>> r = random.randrange(start, stop) # a random number start ≤ r ≤ stop-1 >>> r = random.randint(start, stop) # a random number start ≤ r ≤ stop
stop terminal value. Note also that an optional step parameter
is also allowed for the first form, although we will not need it here.)
Another random utility we will use is one which generates a list
of random choices from some initial population of possibilities. It happens
to return results “with replacement”, which is technical
terminology in probability and statistics: it just means that when choosing
the next value in the list, we consider all the original possibilities,
including any already chosen, so that occasional duplications may occur
in the context of the list.
In particular, this is the choices function, which is documented on
the page cited above as follows:
Note that there are multiple parameters, that all but the first are optional, and that the optional ones are specified by Python’s named parameter feature (so that they can be given in any order, and some skipped, etc.) We will not need anywhere near the full generality of this function, but just a version of the call with a population and a specification of therandom.choices(population, weights=None, *, cum_weights=None, k=1)
k
parameter. This will allow us to get a list of (pseudo-)randomly values from a set:
in the case above with names, these are alphabetic letters; for your numbers case
below, they will be digits or numbers.
We can make a call like this (see the sample file
Names.py and the
section below that describes it):
This call will get usrandom.choices( alphabet, k = random.randrange(min,max) ))
k alphabetic letters in a list, where the
value k is itself a random number between min and
max. (Again, see the file and the description for more context.)
PhoneNum class
In the Names.py file above, I wrote code to generate names as just
two strings … but as we discussed above, it would probably be better to
use something like a real class, and then supply methods to extract the parts
when necessary. In this next section, we discuss a similar module that you will
write, in order to manifest phone numbers for the other half of our general
population of phonebooks and our sample populations for lookup.
You could of course represent
phone numbers as simple 10-digit numbers, or as triples of three integers: area code,
exchange, and number proper. But when we write out phone numbers, we want
them to get formatted something like this: '(503) 555-6767'. And as for
the names above, we should probably make a better design decision in anticipation of
program growth, even if we never extend this simple lab.
One way to do better would be to make the basic triples of ints into a new object
class, one with three instance variables. We could then use the standard
.__str__() and .__repr__() methods to format them these
numbers for printing, etc., in the usual way, but retain the flexibility of a
structure with access methods, etc., in anticipation of program growth.
So this class can (for now) be quite simple: the main task will be to format the
integers so that they have enough leading zeros to look natural: we don't want
'(30)-7-98'
as the format, we want rather '(030)-007-0098' (presuming there
really are valid area codes and exchanges that start with zeroes).
Note that python allows you to say f'{56:04}' and get the
padded string '0056' in return, for example.
Of course, you should also set something up to allow you to get a random phone
number, in much the same way you will have modified my names code to allow for a
random name to be returned, i.e., as the result of an __init__(),
so that you can get new random phone numbers through an object construction like
pn = PhoneNumer(). (Note that will need to use the random
library for these purposes, but you can basically just mimic the code I provided
for names.)
Before you try to actually write out your phonenumber class, think about
what you will need: three integer variables, an init method, a string method, …
and anything else? In a Real World application, we might want to be able to extract
area codes, etc., separately—we won’t need that functionality here, but
it would be easy to provide with a few “getter” methods.
datetime library
Just as we used the random library to form a basis for generating random
names and phone numbers, we ill appeal to the standard python datetime
library for tools to implement our StopWatch class. There are actually
two types of time-related data implemented in this library that we will need, called
datetime (like the library itself) and timedelta. The
datetime class implements a notion of an absolute point on the
“global” timeline that we all live in. In particular, these values are
number-like, but with an “origin” placed at the beginning of the day on
January first, 1990. (Other important standard time origins used widely in computing
include the Unix or Epoch time origin of January 1st, 1970, and the
Universal Time Code (UTC) origin of January 1st, 1972.)
A datetime value denotes a moment in time, an instantaneous point
on the timeline. But the timedelta type represents instead a measure
of time, in the sense of the “length” of a time interval, i.e.,
the amount of time which passes between one point and another on the timeline.
(Famously, time itself passes in only one direction—well, at least for
most
of
us
…).
This interpretation means that although both of these types are sort of like numbers,
in fact only certain arithmetic operations are defined between various combinations
of datetime and timedelta values. In particular, subtracting
two datetime values yields a timedelta value; two of the latter
can be added or subtracted (as this makes sense for intervals), and they can even be
multiplied by numbers (since it makes sense to consider an interval which is several times
as long as another interval). But you cannot add or multiply together two datetime
values, nor multiply them by numbers, as those operations don’t really make sense for
absolute points on the timeline.
As you can see, the issues in representing time-related values are a bit more complex and
subtle than you might have guessed at first—you can read more about these types
and the operations available on them in
the official documentation
for the datetime standard library. (Just note that the description runs to
almost 50 pages!)
StopWatch class[This section still needs some details … ]
You should write this class, based on your preliminary designs from the
past week or so in lab. The design is up to you, but it should probably
have at least some methods to start, stop, reset, read (as in: get the time),
and print (as in the standard .__str__() and
.__repr__() methods).
I made mine so that starting without resetting accumulates the time, but other options could be useful, too.
I ended up using datetime.timedeltas for my StopWatch
class, as they can be added and subtracted from each other, and obtained by
subtracting datetimes in the first place.
OK, with the above preliminaries out of the way, we are finally ready to discuss how we will actually set up the comparative tests for our various implementations of lookup code, namely: python dictionaries, python native lists (of pairs), and your own linked lists (again, of pairs). Recall that for each implementation, we will want to try looking up some sample or test cases in a bigger structure or “phonebook”. So, we will need to generate two populations for each test run, the general population (say: “genpop”) and the smaller sample population.
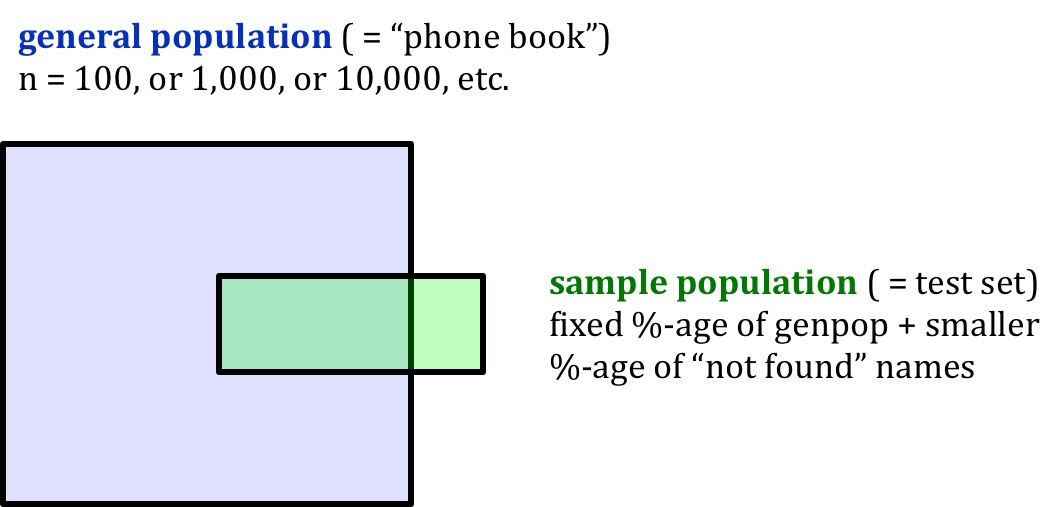
Since we want the lookup tasks to be at least moderately realistic, let’s agree that the sample populations will have both successful and some (fewer) unsuccessful lookups. We can ensure this by first generating the general population data, and then drawing the sample population mostly from the general one we have generated. Since we don’t need to look up every name in order to test things out, let’s also agree that the samples will constitute some standard percentage of the general population, say something like 5% or 10%.
But we might also include some names to look up that we know won’t be found: we can’t guarantee that fresh random names will fit this characterization, but it’s very unlikely that we would happen to generate the same names twice. So we could add another say 2% of the size of the genpop of names that are newly-generated and unlikely to be found: this will more realistically simulate real-world situations where unfound names are usually a possibility. (In a more sophisticated version of this testing, we would need to more about the actual intended uses and data patterns, but again, these simple assumptions are reasonable for a lab exercise.)
Note that we should try to test the various data structure implementations with the same test data in roder to be fair. This means that we should generate our genpop data first, then place it in each structure in turn, and next generate our sample population data (in part drawn from the genpop data), and then finally test the same genpop and samples across each of the three implementations structures. One way to do this would be to generate into python lists for simplicity, then convert the data from the python lists into dictionary form and linked list form. (And note that we are not too worried here about how long the conversion process takes, just the lookups at the end, once everything is generated.)
To be more concrete, then, you might develop your populations as follows:
In a bit more detail …
In order to generate some phonebooks and sample populations,
it is convenient to first generate the “base data”, a list
of names and a list of phone numbers, first, and only then
populate the data structures in question (dictionary, python
list, linked list). Why? If we generate the names and numbers
directly into a dictionary, for example, the python standard
random library will not be able to extract a sample
population from it.
Assuming we have a variable n that corresponds to the desired
number of names and phonenums:
First generate the “base” lists:
namelist = ... # generate n names numlist = ... # generate n phone numbers
Next, populate the phonebooks from these lists:
genpopdict = ... # put values from namelist and numlist into a dict genpopplist = ... # put values from namelist and numlist into a python list of pairs genpopllist = ... # put values from namelist and numlist into a linked list of pairs
Now, we can generate a sample population as follows: we want some standard fraction (say 5% or so) of the names from the original namelist, plus a fsmaller bunch of “fresh” names (not expected to be found in the phonebook) which we might then “shuffle” (using a random library call) into a final list of names to use for sampling or testing purposes.
samppop = ... # choose 5% of namelist + add some more (0.2%?) of "fresh names" sampop.shuffle(...) # check the random libraries fro the correct call
Now we can try looking up the sample names in each of the three phonebooks (dict, plist, and llist):
for name in samppop:
# lookup n in genpopdict
for name in samppop:
# lookup n in genpopplist
for name in samppop:
# lookup n in genpopllist
Here is some sample output from my own implementation:
5 samples from python list population of 100 took 0:00:00.000016
5 samples from linked list population of 100 took 0:00:00.000033
5 samples from python dict population of 100 took 0:00:00.000004
52 samples from python list population of 1000 took 0:00:00.001730
52 samples from linked list population of 1000 took 0:00:00.002051
52 samples from python dict population of 1000 took 0:00:00.000014
520 samples from python list population of 10000 took 0:00:00.136822
520 samples from linked list population of 10000 took 0:00:00.139762
520 samples from python dict population of 10000 took 0:00:00.000101
5200 samples from python list population of 100000 took 0:00:15.184087
5200 samples from linked list population of 100000 took 0:00:14.958131
5200 samples from python dict population of 100000 took 0:00:00.001354
Try timing inside the loop versus outside the loop; does it make a difference? Can you speculate why?
Try timing the generation of your genpop list versus your genpop dict, for various sizes. Are they similar or different? Do the timings vary in the same way as they do for the lookup?
We made objects out of three-part phone numbers, but not out of two-part names;
should we have? Will lookup for lists and .get() for
dictionaries work if we pass them objects as “keys”?
There are some tricky issues with equality here:
how can we make things work intuitively?
Dictionaries sound great! Maybe we should make a PhoneBook class
which wraps up this sort of dictionary and gives it some useful methods.
It could even print out in the usual format, sorted alphabetically by last
name … can we therefore just print the dictionary out directly, using
its .__str__() function? Why or why not?
{kind=link}
{kind=link}
{kind=link}